MVP: Unified Motion and Visual Self-Supervised Learning for Large-Scale Robotic Navigation
ArXiv Preprint 2020
Abstract
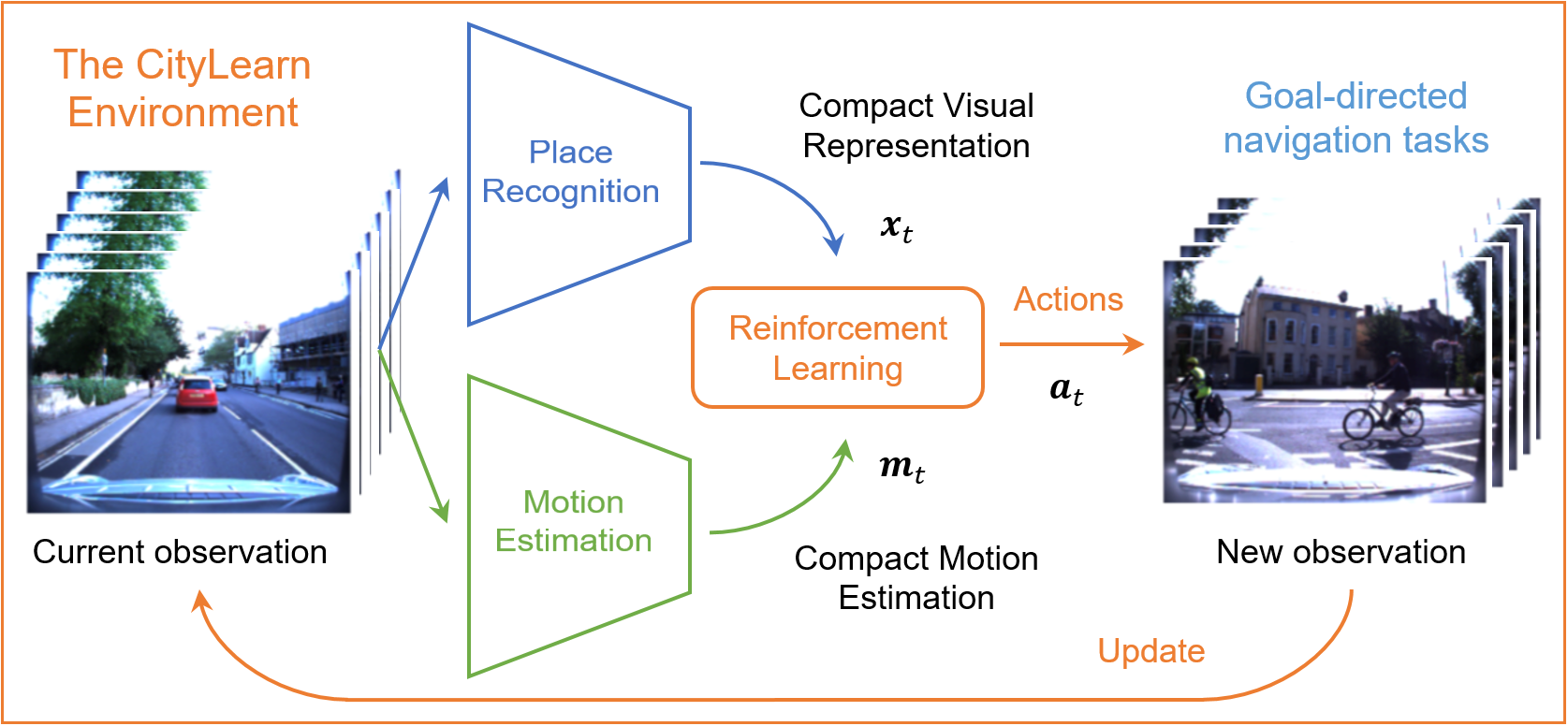
Autonomous navigation emerges from both motion and local visual perception in real-world environments. However, most successful robotic motion estimation methods (e.g. VO, SLAM, SfM) and vision systems (e.g. CNN, visual place recognition–VPR) are often separately used for mapping and localization tasks. Conversely, recent reinforcement learning (RL) based methods for visual navigation rely on the quality of GPS data reception, which may not be reliable when directly using it as ground truth across multiple, month-spaced traversals in large environments. In this paper, we propose a novel motion and visual perception approach, dubbed MVP, that unifies these two sensor modalities for large-scale, target-driven navigation tasks. Our MVP-based method can learn faster, and is more accurate and robust to both extreme environmental changes and poor GPS data than corresponding vision-only navigation methods. MVP temporally incorporates compact image representations, obtained using VPR, with optimized motion estimation data, including but not limited to those from VO or optimized radar odometry (RO), to efficiently learn self-supervised navigation policies via RL. We evaluate our method on two large real-world datasets, Oxford Robotcar and Nordland Railway, over a range of weather (e.g. overcast, night, snow, sun, rain, clouds) and seasonal (e.g. winter, spring, fall, summer) conditions using the new CityLearn framework; an interactive environment for efficiently training navigation agents. Our experimental results, on traversals of the Oxford RobotCar dataset with no GPS data, show that MVP can achieve 53% and 93% navigation success rate using VO and RO, respectively, compared to 7% for a vision-only method. We additionally report a trade-off between the RL success rate and the motion estimation precision, suggesting that vision-only navigation systems can benefit from using precise motion estimation techniques to improve their overall performance.Preprint: [PDF] arXiv: [ABS] CityLearn environment: [GitHub]
Bibtex
@article{chancan2020mvp,
author = {M. {Chanc\'an} and M. {Milford}},
title = {MVP: Unified Motion and Visual Self-Supervised Learning for Large-Scale Robotic Navigation},
journal = {arXiv preprint arXiv:2003.00667},
year = {2020}
}